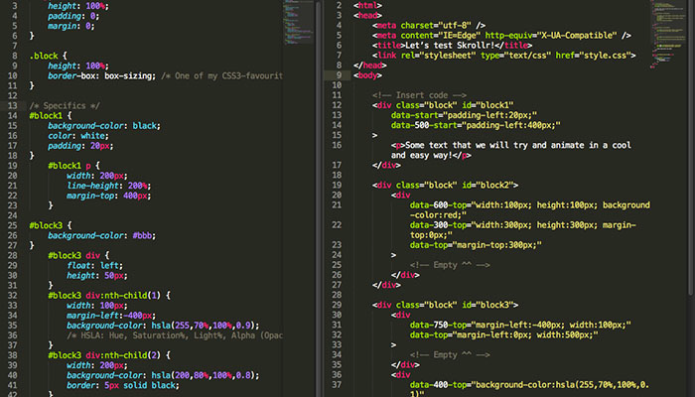
Ever scrolled down a website and been amazed that objects doesn't behave like you expect them to? Instead of flowing static content upwards on the screen as we scroll we can now easily animate them in any way. Fly text sideways, zoom in images, fade out objects, and more!